在全球人工智能技术竞争日益激烈的背景下,日本正通过自主研发加速芯片寻求技术自主权。尽管当前可采购英伟达最先进的AI显卡,但为避免技术依赖风险,日本企业仍在推进定制化浮点加速芯片的研发。由日本新能源产业技术综合开发机构(NEDO)资助的Pezy Computing KK公司,成为这一战略的关键参与者。

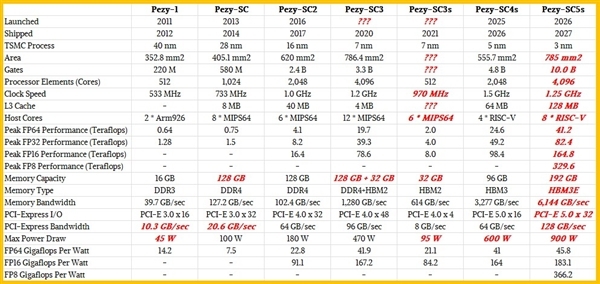
该公司自2012年推出首代Pezy芯片以来,已形成完整的技术迭代路径。在近期举办的Hotchips 25会议上,其宣布的Pezy-SC4系列芯片计划于2026年正式商用。该芯片采用台积电5纳米制程工艺,集成48亿个晶体管,配备2048个计算核心,主频达1.5GHz。其内存子系统配置64MB三级缓存与96GB HBM3显存,整机功耗控制在600瓦水平。在计算性能方面,FP64双精度浮点运算峰值达24.6TFLOPS,FP32单精度与FP16半精度运算分别实现49.2TFLOPS和98.4TFLOPS。
更值得关注的是其下一代产品Pezy-SC5的规划。这款采用台积电3纳米工艺的芯片,晶体管数量将突破100亿大关,核心数量翻倍至4096个。内存系统升级为192GB HBM3e显存,功耗提升至900瓦。性能指标显示,其FP8低精度运算峰值可达329.6TFLOPS,同时完整支持从FP64到FP8的多精度计算格式。这种全谱系计算能力设计,使其在科学计算与AI训练场景中具备独特优势。
在能效比方面,Pezy系列芯片展现出强劲竞争力。实测数据显示,SC4系列的FP64能效达41gflops/w,SC5系列更提升至45.8gflops/w。对比英伟达当前产品线,H200芯片的FP64能效为47.9gflops/w,B200为33.3gflops/w,而专为AI训练优化的B300由于大幅削减FP64计算单元,能效骤降至0.89gflops/w。这种对比凸显日本芯片在高精度计算领域的能效优势,尤其在需要双精度运算的气候模拟、分子动力学等科学计算场景中更具竞争力。
日本的技术路线选择折射出其产业战略考量。通过定制浮点加速架构,Pezy芯片在保持与英伟达GPU相当综合性能的同时,在特定计算场景中实现了能效超越。这种差异化竞争策略,既避免了与英伟达在通用AI加速领域的正面交锋,又为日本在超算、工业仿真等关键领域保留了技术自主权。随着2030年日本计划推出基于英伟达下下代GPU的Z级超算FugakuNEXT,这种"双轨并行"的技术发展模式,或将重塑全球高性能计算领域的竞争格局。
可查的实盘配资公司提示:文章来自网络,不代表本站观点。
- 上一篇:专业炒股配资咨询对国民经济的稳定和发展具有关键作用
- 下一篇:没有了